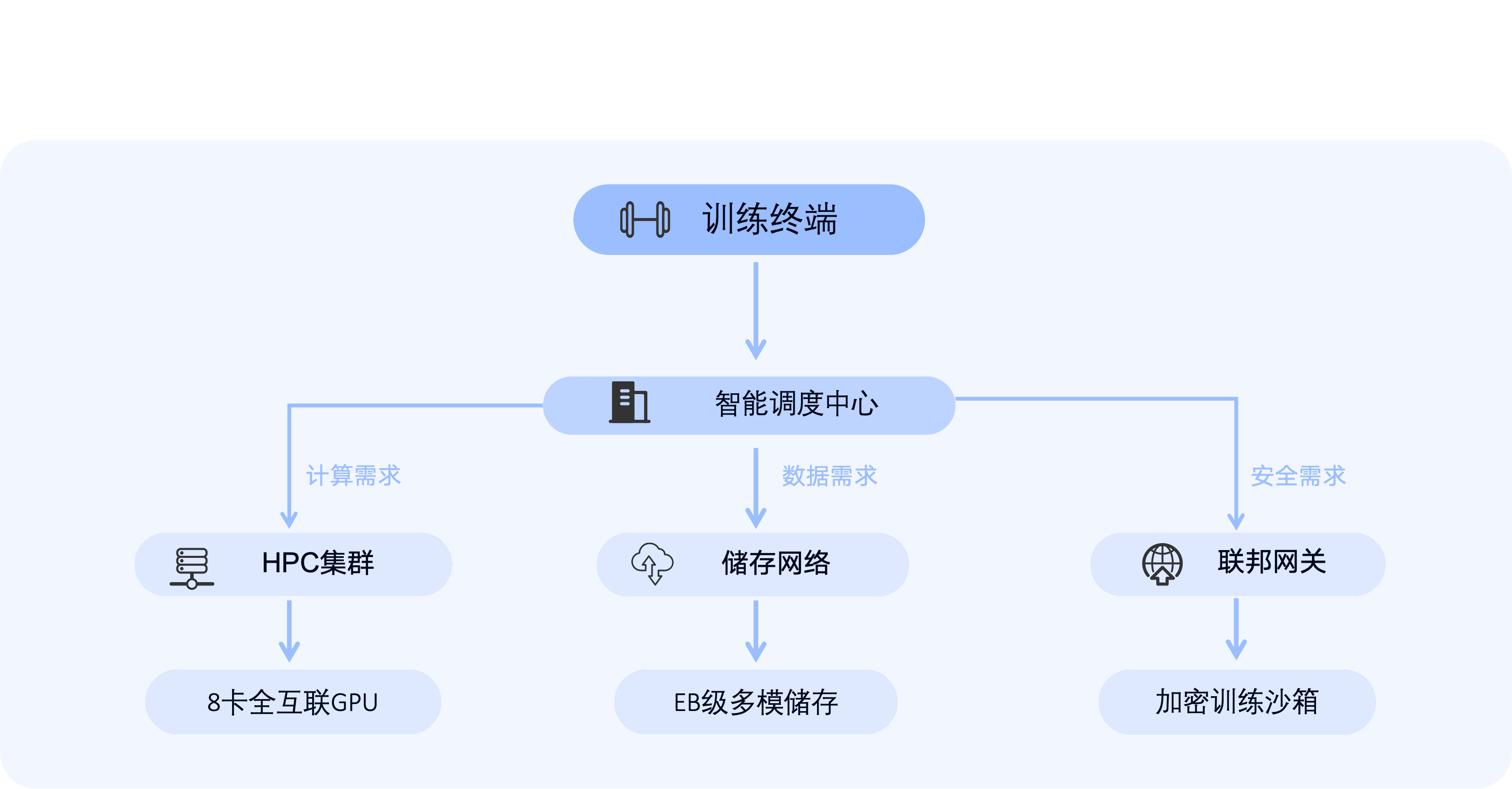
 超大规模集群部署
超大规模集群部署
- 单区域最大支持1000卡互联,NVLink全互联带宽达900GB/s
- 支持Kubernetes/Megatron-LM等分布式训练框架开箱即用
 弹性裸金属服务
弹性裸金属服务
- 分钟级开通NVIDIA H200/A100物理集群,支持1-1000卡弹性扩展
- 硬件隔离保障多租户数据安全,SSH权限100%自主控制
 智能算力调度
智能算力调度
- 跨60国节点智能负载均衡,训练任务排队时间缩短85%
- 中断恢复 可视化监控所有计算节点状态,支持优先级调度与中断恢复
 全球合规保障
全球合规保障
- 符合欧盟AI法案/美国出口管制条例,芯片级使用追溯系统
- 热点区域(新加坡/法兰克福)配备A100/H100双合规集群
175B参数模型训练周期过长
跨国数据传输效率低下
GPU资源利用率不足45%
成效
↓
训练时间从89天缩短至23天,TCO降低41%
成效
↓
检查点同步速度提升8倍,数据丢失率归零
成效
↓
集群利用率稳定在82%,闲置成本减少67%

GPU裸金属BMS
- NVIDIA H200/A100/5090可选,单节点8卡全互联拓扑
- 配套3.2Tbps超低延迟网络网络,延迟<1.5μs

混合云训练平台
- 直接对接AWS/GCP等主流AI训练平台
- 支持vGPU切分,最小0.5卡时粒度计费

全球数据高速公路
- 60+国家专线互联,单流传输速率达400Gbps
- 海底光缆+卫星双保险,可用性99.999%