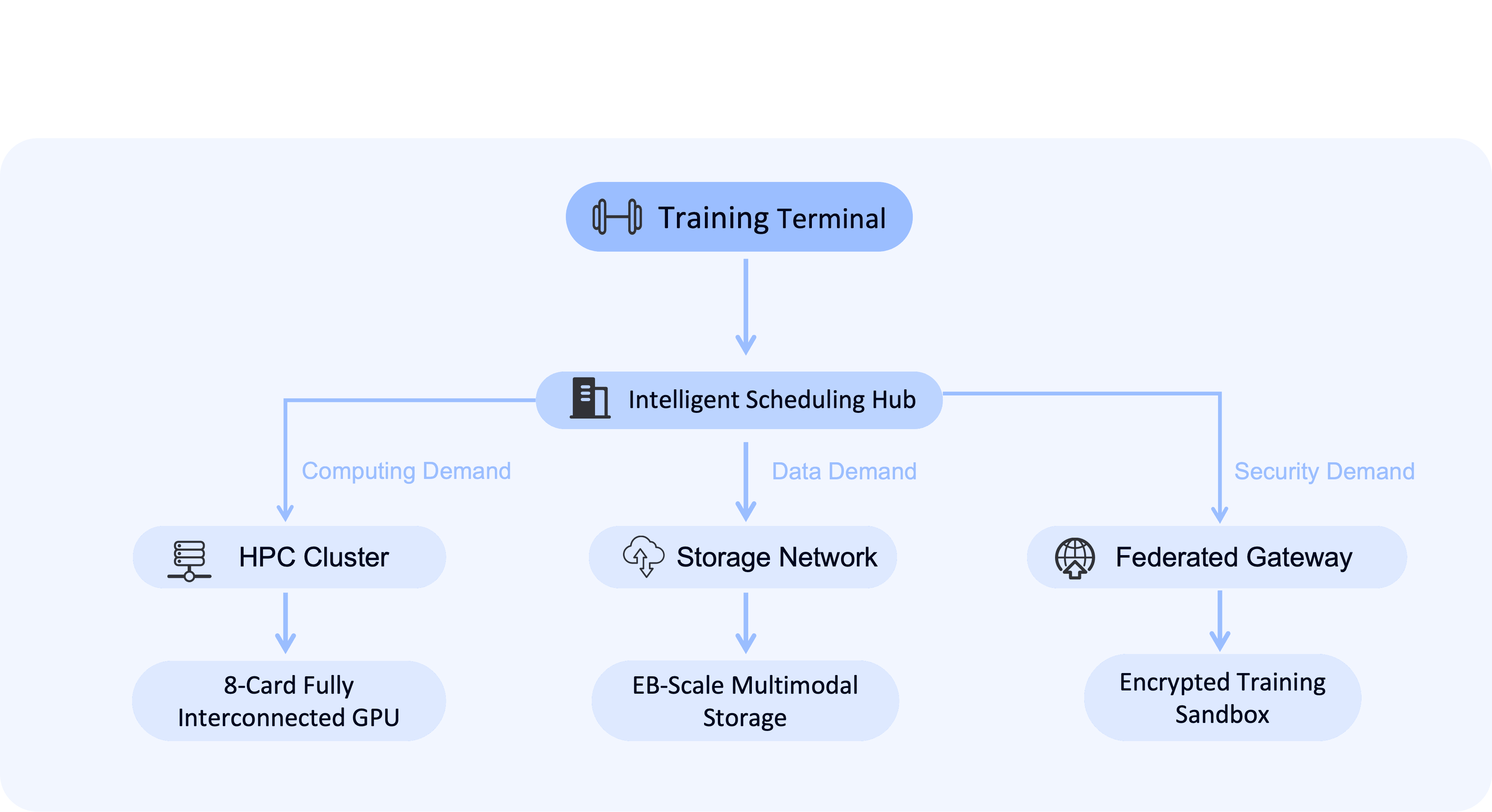
 Hyperscale Cluster Orchestration
Hyperscale Cluster Orchestration
 Hyperscale Cluster Orchestration
Hyperscale Cluster Orchestration- 1,000+ GPU interconnects per region with 900GB/s NVLink full-mesh bandwidth
- Native support for Kubernetes/Megatron-LM distributed frameworks.
Bare-Metal Elasticity
 Bare-Metal Elasticity
Bare-Metal Elasticity- Spin up NVIDIA H200/A100 clusters in minutes (1-1,000 GPUs on demand)
- Hardware-isolated multi-tenancy with full SSH control.
Intelligent Compute Scheduling
 Intelligent Compute Scheduling
Intelligent Compute Scheduling- Global load balancing across 60+ nodes cuts job queue times by 85%
- Live compute node monitoring with smart scheduling and auto-recovery
Compliance-Ready Infrastructure
 Compliance-Ready Infrastructure
Compliance-Ready Infrastructure- EU AI Act/U.S. export control compliance with chip-level audit trails
- Dual-certified A100/H100 clusters in Singapore/Frankfurt hotspots.
175B-param model
training bottlenecks Cross-border data
transfer delays <45% GPU
utilization rates
training bottlenecks Cross-border data
transfer delays <45% GPU
utilization rates
Outcome
↓
Training time reduced from 89→23 days, 41% TCO savings.
Outcome
↓
Checkpoint sync 8x faster, zero data loss.
Outcome
↓
82% sustained utilization, 67% idle cost reduction.

Bare-Metal GPU Clusters
- NVIDIA H200/A100/5090 options, 8-GPU full-mesh topology per node
- 3.2Tbps ultra-low-latency network (<1.5μs)

Hybrid Training Platform
- Direct integration with AWS/GCP AI ecosystems
- vGPU partitioning (billable per 0.5 GPU-hour).

Global Data Expressway
- 60+ country dedicated lines (400Gbps/stream)
- 99.999% uptime via subsea cables + satellite redundancy